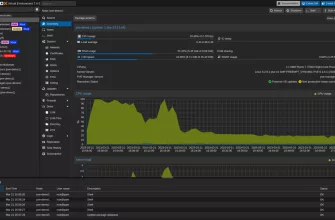
На днях мы столкнулись с неприятным инцидентом в ЦОД. Один из двух наших физических серверов подхватил зловреда, похожего на шифровальщика. Несмотря на наличие средств защиты (Касперский), компрометация произошла.
К счастью, инцидент был замечен быстро, и фатальных последствий для данных удалось избежать. Но ситуация заставила меня полностью переосмыслить текущий подход к инфраструктуре.
Главный вывод: Монолит — это зло.

До этого момента ключевые сервисы (1С, MS SQL, RDP-сервер для разработчиков) жили на одной физической машине (Сервер 2). ИБ-инцидент наглядно показал: любая проблема на этом хосте — будь то зловред, неудачное обновление ОС или аппаратный сбой — парализует всю работу компании. Это недопустимый бизнес-риск.
Век виртуализации наступил давно, и наша инфраструктура очевидно от него отстала. Пора это исправлять.
Я, хоть и директор, глубоко погружен в технические процессы компании. Я убежден, что, прежде чем нанимать администратора или подрядчика для построения новой архитектуры, я должен сам хорошо понять другие варианты, риски и лучшие практики. Только так можно сформировать грамотное ТЗ и принять правильное решение.
Что мы имеем (Дано):
1. ЦОД:
- 4 «белых» IP-адреса.
- Маршрутизатор Mikrotik для управления трафиком.
- Канал 200 Мбит/с.
2. Сервер 1 (Младший хост):
- 1U Supermicro, 2 x Xeon E5-2650 v3.
- 190 ГБ ОЗУ.
- SSD-накопители (2 x 480 ГБ Intel, 1 x 960 ГБ Intel).
- Ранее использовался для демо-сервера 1С, бэкапов с Сервера 2 и тестовых VM.
3. Сервер 2 (Старший хост):
- 2U HPE 10 Gen, 2 x Intel XEON 6248R.
- 512 ГБ ОЗУ.
- Высокопроизводительные накопители (SAS SSD 1.6 ТБ x2, NVMe PCI-E 3.2 ТБ x1).
- Архивные HDD (SAS 16 ТБ x2).
- Ранее нес на себе всю основную нагрузку: 1С, MS SQL, RDP, GitLab, GitLab-раннеры, тестовые Linux-машины.
Для Сервера 2 уже заказан апгрейд, который добавит еще 256 ГБ ОЗУ, пару быстрых SAS SSD PM1643a по 3.84 ТБ и дополнительный HDD Exos на 18 ТБ.
Первый сервер послабее, второй достаточно не плохой. Использовать их как два изолированных «монолита» — преступление.
Постановка задачи: Новая архитектура
Цель — построить отказоустойчивую, безопасную и масштабируемую инфраструктуру, используя имеющееся железо.
Очевидный путь — виртуализация. Но просто разнести сервисы по VM на одном хосте — это полумера, которая не решает проблему отказа самого хоста.
Поэтому я думаю о построении HA-кластера (High Availability) на базе двух этих серверов.
В идеале при падении физического Сервера 2 все его критичные виртуальные машины (1С, SQL, RDP) должны автоматически перезапуститься на Сервере 1 с минимальным простоем.
Это порождает три главных архитектурных вопроса, по которым я и хочу посоветоваться с сообществом.
Вопросы к профи:
1. Платформа виртуализации для HA-кластера
Что выбрать для построения отказоустойчивого кластера на двух нодах?
- Hyper-V (Failover Cluster): Логичный выбор для Windows-экосистемы. Но как лучше организовать общее хранилище? Использовать Storage Spaces Direct (S2D), связывая две ноды, или это избыточно и лучше купить/собрать отдельный NAS/SAN?
- Proxmox VE: Выглядит очень привлекательно. Open-source, HA-кластер и бэкапы «из коробки», отлично работает с Linux VM (KVM). Насколько он стабилен для высоконагруженных Windows-машин (MS SQL, 1C, RDP)? Кто использует в проде, какие подводные камни?
- VMware vSphere (HA): Классика. Но что сейчас с лицензированием после поглощения Broadcom? Не станет ли это слишком дорого и трудно для двух хостов?
2. Сетевая изоляция (VLAN и безопасность)
Просто разнести сервисы по VM недостаточно. Если зловред попадет в одну VM, он не должен иметь доступ к другим. Я планирую использовать Mikrotik для жесткой сетевой сегментации (VLAN). Например:
VLAN 10 (Management): Доступ к хостам виртуализации, Mikrotik.VLAN 20 (Production): Серверы 1С, MS SQL, Контроллер домена.VLAN 30 (Users): RDP-ферма для удаленных сотрудников и разработчиков EDT.VLAN 40 (DMZ/Test): GitLab, тестовые Linux-машины, раннеры.
Как вы настраиваете правила Firewall для таких сегментов? Например, разрешить VLAN 30 доступ к VLAN 20 только по портам MS SQL (1433) и 1С, а весь остальной трафик для них запретить. Какие здесь лучшие практики?
3. Отказоустойчивые бэкапы
Инцидент показал, что бэкапы, лежащие на соседнем сервере в той же сети, — не панацея. Шифровальщик мог бы легко добраться и до них. Нужна система по правилу 3-2-1. Как минимум одна копия должна быть «неизменяемой» (immutable) или находиться физически/логически вне ЦОД (off-site).
- Какой софт используете для бэкапа VM в кластере (Veeam, Acronis, Proxmox Backup Server)?
- Куда лучше всего отправлять третью копию (S3-совместимое облако, съемные диски, другой ЦОД)?
Цель — построить прочный фундамент для ИТ-инфраструктуры, который переживет и сбой железа, и атаку, не останавливая бизнес. Буду благодарен за любой конструктивный совет и обмен реальным опытом.